Bayesian vs Frequentist Statistics in Information Science

Picture by Writer
Earlier than we get into the variations between Bayesian and frequentist statistics, let’s begin with their definitions.
When utilizing statistical inference, you’re making judgments concerning the parameters of a inhabitants utilizing knowledge.
Bayesian inference takes into consideration prior information, and the parameter is taken as a random variable. That means there’s a likelihood that the occasion will happen. For instance, if we have been to flip a coin, Bayesian inference will state that there isn’t a unsuitable or proper reply, and the likelihood of the coin touchdown on heads or tails is all the way down to their perspective.
The Bayesian perspective is predicated on Bayes’ Theorem, a components that takes under consideration the likelihood of an occasion based mostly on prior information. The components is proven under, the place:
- P(A): the likelihood of A occurring
- P(B): the likelihood of B occurring
- P(A|B): the likelihood of A given occasion B
- P(B|A): the likelihood of B given occasion A
- Pr(A|B): the posterior, the likelihood of the parameters given the info.
Picture by Wikipedia
Folks that have a Bayesian mindset, view and use chances to measure the chance of an occasion taking place. It’s what they consider. The likelihood of a speculation is calculated and deemed true utilizing prior opinions and information as new knowledge is available. That is known as prior likelihood, which is concluded earlier than the undertaking begins.
This prior likelihood is then transformed right into a posterior likelihood, the assumption as soon as the undertaking has began.
Prior + Chance = Posterior
Frequentist inference is completely different. It assumes that occasions are based mostly on frequencies, and the parameter isn’t a random variable- which means there isn’t a likelihood. Utilizing the identical instance as above, should you have been to flip a coin – frequentist inference will state that there’s a appropriate reply based mostly on frequency. Should you have been to toss a coin and get tails half of the time, then the likelihood of getting tails is 50%.
There’s a stopping criterion put in place. The stopping rule determines the pattern house, subsequently information about it’s important for frequentist inference. For instance, with the coin toss a frequentist method might repeat the check 2000 occasions, or till it is landed on 300 tails. Researchers don’t sometimes repeat checks this period of time.
Folks that have a Frequentist mindset, view and deal with likelihood the identical as frequencies. Their likelihood will depend on one thing taking place if it have been to be infinitely repeated.
From a frequentist’s perspective, the parameters you employ to estimate your inhabitants are assumed to be fastened. There’s a single true parameter that you’ll estimate and isn’t modeled as a likelihood distribution. When new knowledge is obtainable, you’ll use it to carry out statistical checks and make chances concerning the knowledge.
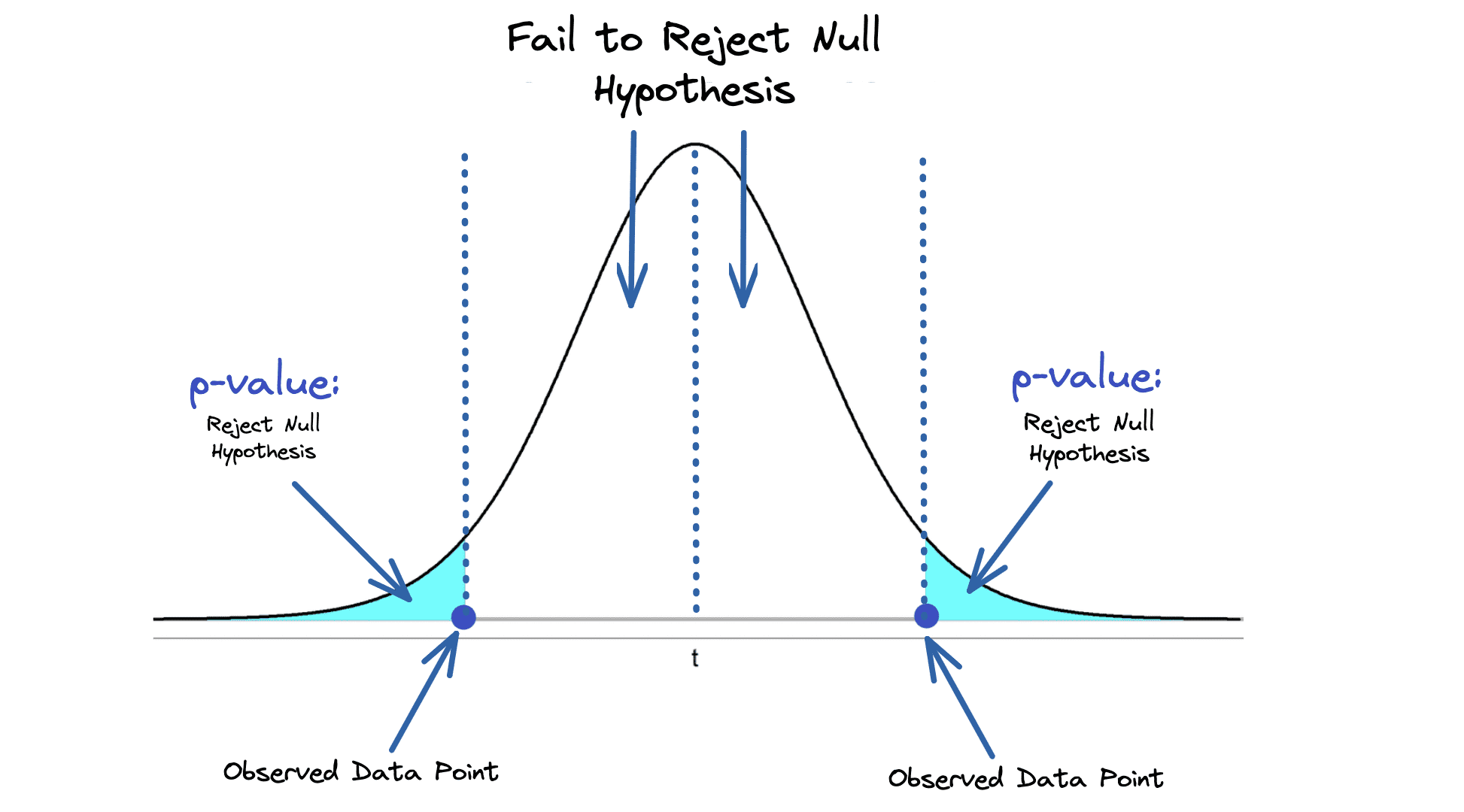
The most well-liked computation in frequentist statistics is the p-value, a statistical measurement used to validate your hypotheses. It describes how doubtless you might be to have discovered a selected set of observations if the null speculation (no statistical relationship) is appropriate.
The shaded blue space within the picture under reveals the p-value, the likelihood of an noticed outcome occurring by likelihood.
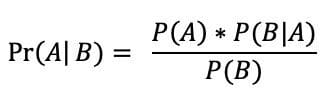
Picture by Writer
Statistics is a large a part of Information Science, and should you’re a part of that world – you have got come throughout Bayes’ Theorem, p-value, and different statistical checks. It advantages you as a Information Scientist or somebody who works with knowledge to have understanding of statistical evaluation and the instruments on the market. There could also be a time that you’ll require them.
Inside your staff, as you might be discussing tasks and your subsequent steps – you’ll begin to see who has a Bayesian mindset and who has a Frequentist mindset. Information Scientists will work on probabilistic forecasting which mixes residual variance with estimated uncertainty. That is particularly a Bayesian framework. Nevertheless, it doesn’t rule out some specialists wanting to make use of a frequentist method.
Relying on the method you’re taking displays on the statistical strategies you select. Lots of the basics of information science are constructed on Bayesian statistics, and a few even view frequentist approaches to be a subset of Bayesian principle.
Nevertheless, in terms of knowledge science, your focus is on the issue at hand. Many knowledge scientists select their fashions based mostly on the issue they’re making an attempt to resolve. The higher hand that Bayesian approaches have is that on the planet of information science, having particular information about the issue is all the time a bonus.
Bayesian strategies are identified to be sooner, interpretable, user-centered, and have a extra intuitive method to evaluation.
I’ll go into these additional under and the variations between the 2.
Sooner Studying
A Bayesian method begins with an preliminary perception, which is backed by gathering proof. This ends in sooner studying as you have got proof to help your assertion.
A Frequentist method bases their opinions on info obtained from the info. Though they’ve had a have a look at the info, there has not been any evaluation carried out to make sure that is proof. There aren’t any calculations of the likelihood to again the speculation.
Interpretable
Bayesian strategies have a wide range of versatile fashions, permitting them to be utilized to advanced statistical issues. This permits for Bayesian strategies to be extra simply interpretable.
Frequentist strategies are sadly not that versatile and sometimes fail.
Person-centered
The 2 strategies have completely different approaches. The Bayesian technique permits for various research and inquiries to be included within the undertaking dialog. There’s a give attention to possible impact sizes.
Whereas, frequentist strategies limitate this risk because it focuses on unsure significance.
| Attributes: | Bayesian: | Frequentist: |
| What’s it? | Likelihood distribution across the parameters | Parameters are fastened and a single level |
| What does it query? | Given the info, what’s the likelihood of the speculation? | Is the speculation true or false? |
| What does it require? | Prior information/info and any dataset. | A stopping criterion |
| What does it output? | A for or towards likelihood concerning the speculation. | level estimate (p-value) |
| Essential benefit | Backed up with proof and might apply new info | They’re easy and straightforward to make use of, and doesn’t want prior information |
| Essential drawback | Requires superior statistics | Extremely depending on the pattern dimension, and solely give a sure or no output |
| When ought to I take advantage of it? | Restricted your knowledge when you have got priors
Makes use of extra computing energy |
With a considerable amount of knowledge |
I hope this weblog has given you a greater understanding of the distinction between Bayesian approaches and Frequentist approaches. There was a variety of going forwards and backwards between the 2, and if one even exists with out the opposite. My recommendation is to stay to what makes you’re feeling snug and the way your mind breaks issues down via your private logic.
If you would like a deeper dive, the place you possibly can apply your abilities and information, I might advocate: Statistics Crash Course for Beginners: Theory and Applications of Frequentist and Bayesian Statistics Using Python
Nisha Arya is a Information Scientist, Freelance Technical Author and Neighborhood Supervisor at KDnuggets. She is especially thinking about offering Information Science profession recommendation or tutorials and principle based mostly information round Information Science. She additionally needs to discover the other ways Synthetic Intelligence is/can profit the longevity of human life. A eager learner, searching for to broaden her tech information and writing abilities, while serving to information others.





