What’s Okay-Means Clustering and How Does its Algorithm Work?


Picture from Bing Picture Creator
Basically, there are 4 forms of machine studying algorithms; supervised algorithms, semi-supervised algorithms, unsupervised algorithms and reinforcement studying algorithms. Supervised algorithms are people who work on knowledge that has labels. Semi-supervised is the place a part of the information is labeled and one other half is just not. Unsupervised is the place the information doesn’t have labels. Reinforcement studying is a kind of machine studying the place we’ve got an agent that works in direction of a sure purpose and does it by trial and error. The agent will get rewarded when appropriate and will get penalized when incorrect.
Our focus is on an unsupervised machine studying algorithm, Okay-Means clustering algorithm specifically.
Okay-Means is an unsupervised machine studying algorithm that assigns knowledge factors to one of many Okay clusters. Unsupervised, as talked about earlier than, signifies that the information doesn’t have group labels as you’d get in a supervised drawback. The algorithm observes the patterns within the knowledge and makes use of that to position every knowledge level into a bunch with related traits. After all, there are different algorithms for fixing clustering issues akin to DBSCAN, Agglomerative clustering, KNN, and others, however Okay-Means is considerably extra in style compared to different approaches.
The Okay refers back to the distinct groupings into which the information factors are positioned. If Okay is 3, then the information factors can be cut up into 3 clusters. If 5, then we’ll have 5 clusters.. Extra on this later.
There are a myriad methods through which we will apply clustering to resolve actual world issues. Beneath are just a few examples of the purposes:
- Clustering prospects: Corporations can use clustering to group their prospects for higher goal advertising and understanding their buyer base.
- Doc classification: Group paperwork primarily based on the subjects or key phrases within the content material.
- Picture segmentations: Clustering picture pixels earlier than picture recognition.
- Grouping college students primarily based on their efficiency: You might cluster them into prime performers, common performers, and use that to enhance studying expertise.
The algorithm runs an preliminary iteration the place the information factors are randomly positioned into teams, whose central level is called centroid is calculated. The euclidean distance of every knowledge level to the centroids is calculated, and if the space of a degree is increased than to a different centroid, the purpose is reassigned to the ‘different’ centroid. When this occurs, the algorithm will run one other iteration and the method continues till all groupings have the minimal inside group variance.
What we imply by having a minimal variability inside a bunch is that the traits of observations in a bunch ought to be as related as potential.
Think about a dataset with two variables plotted as under. The variables might be the peak and weight of people. If we had a 3rd variable like age, then we’d have a 3-D diagram, however for now, let’s stick with the 2-D diagram under.
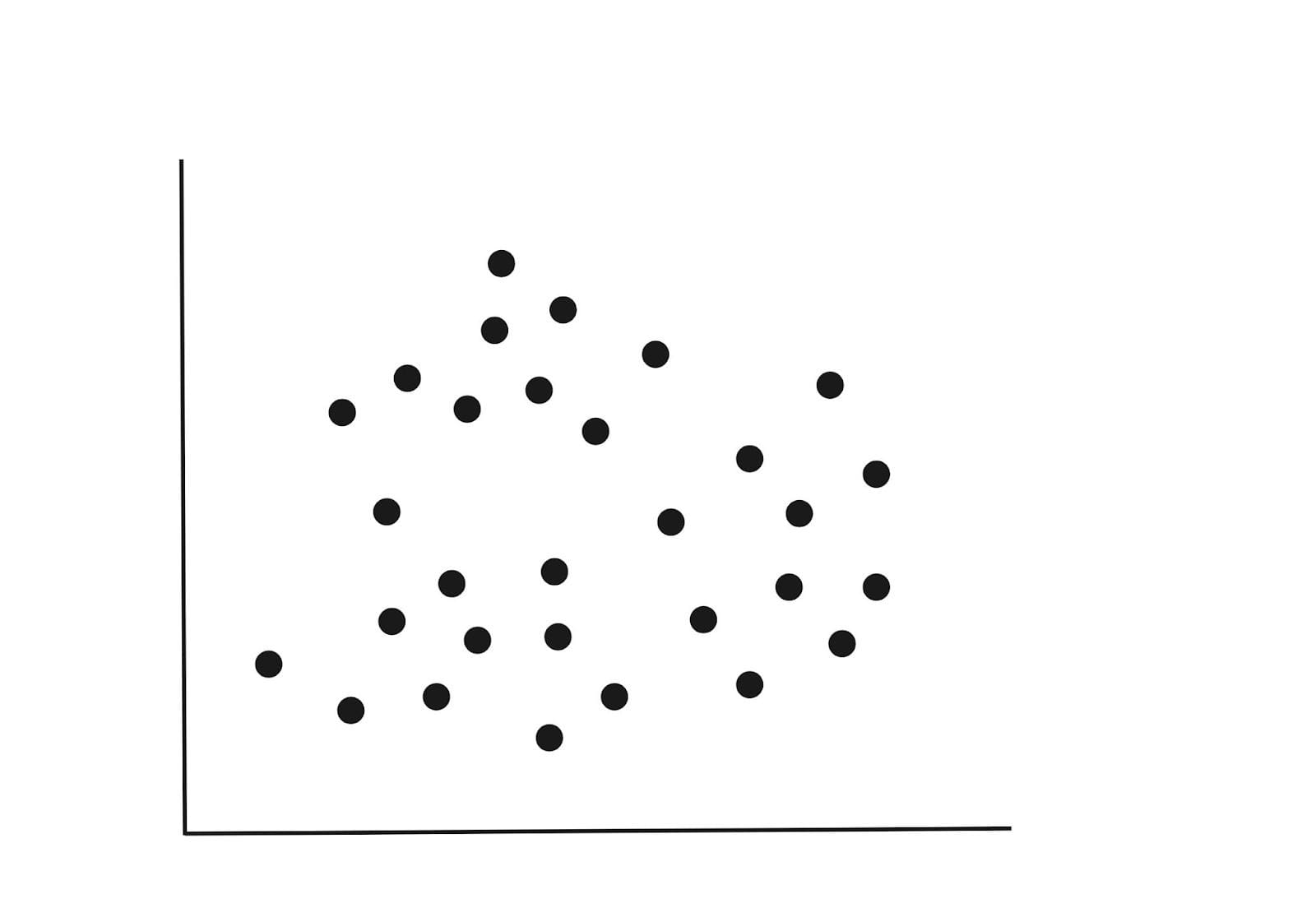
Step 1 : Initialization
From the above diagram we will spot three clusters. When becoming our mannequin, we will randomly assign okay=3. This merely means we’re looking for to separate the information factors into three groupings.
Within the preliminary iteration, the Okay centroids are randomly chosen within the instance under.
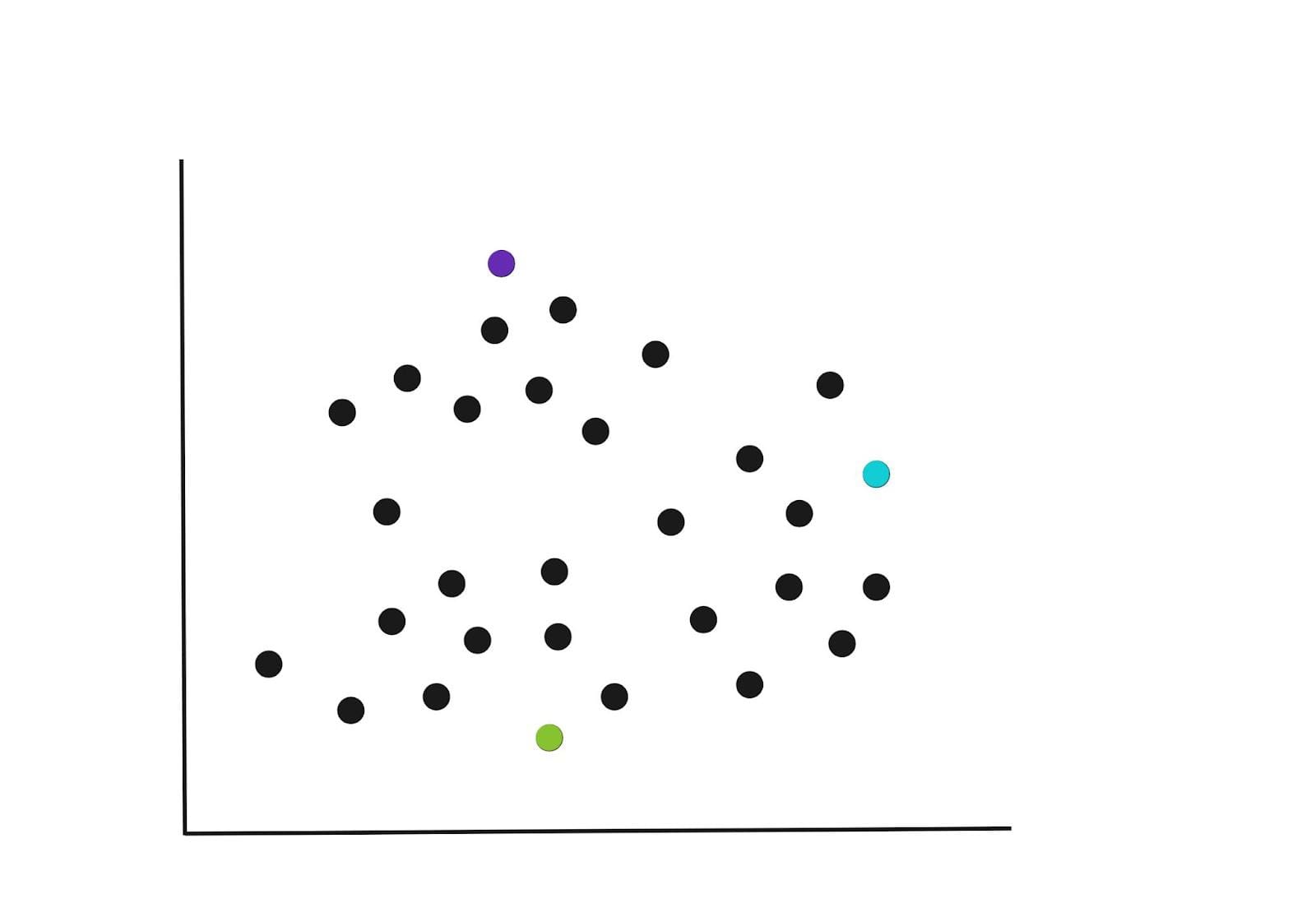
You possibly can specify the variety of Okay-Clusters that the algorithm ought to group the information factors into, nonetheless, there’s a greater strategy to this. We’ll dive into how to decide on Okay later.
Step 2 : Assign factors to the one of many Okay centroids
As soon as the centroids have been chosen, every knowledge level is assigned to the closest centroid, primarily based on the euclidean distance of the purpose to the closest centroid. This might end result within the groupings proven within the graph under.
Observe that different forms of distance measures can be utilized as manhattan distance, spearman correlation distance, and Pearson correlations distance as an alternative choice to euclidean, however the classical ones are euclidean and manhattan.
Step 3 : Recompute the centroids
After the primary spherical of groupings, new centre factors are recalculated once more and this may necessitate a re-assignment of the factors. The graph under provides an instance of how the brand new groupings may probably be, and see how some factors have been moved into new clusters.

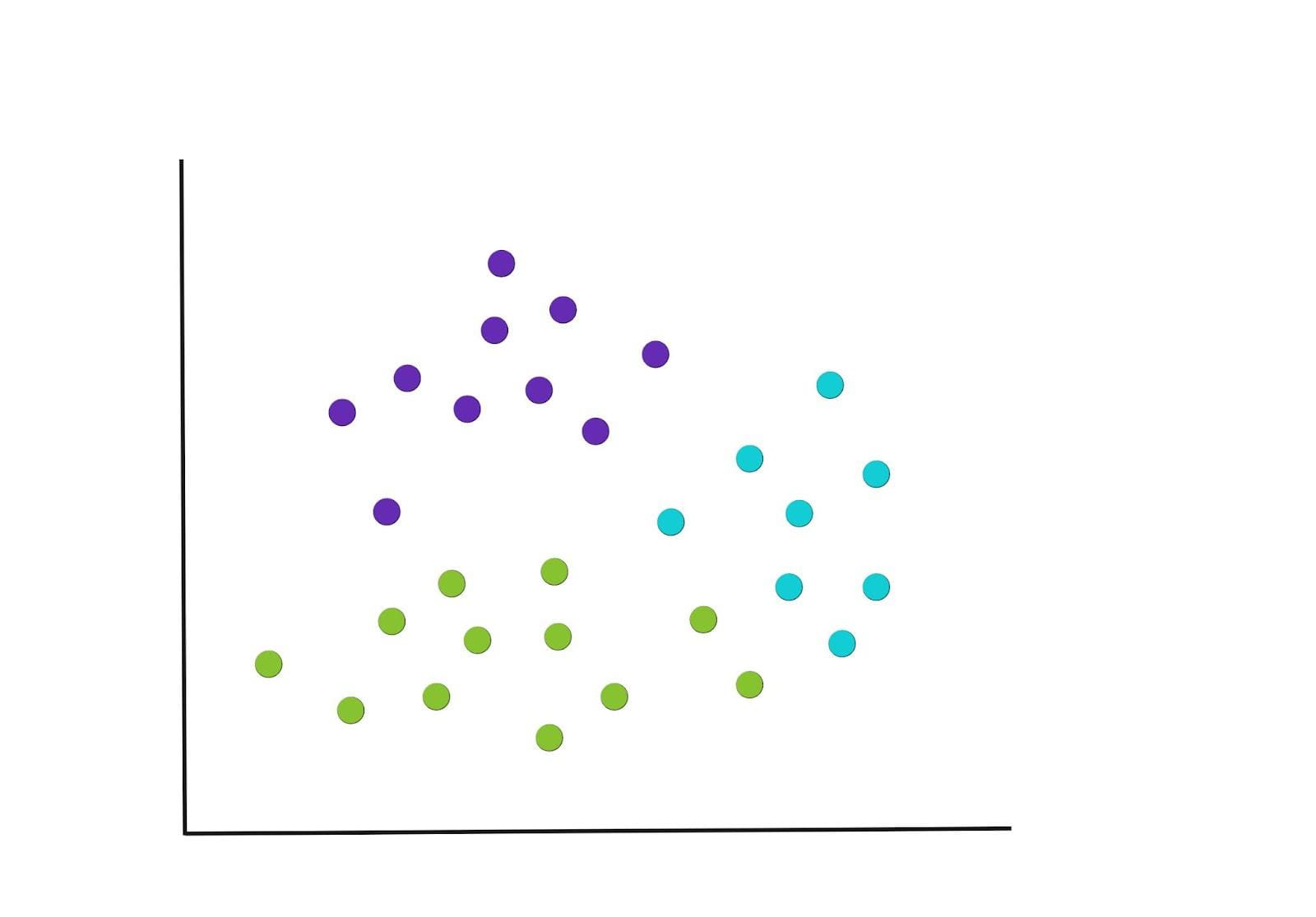
Iterate
The method in steps 2 and three is repeated till we get to some extent the place there aren’t any extra reassignments of the information factors or we attain the utmost variety of iterations. The ensuing closing groupings are under.

The selection of Okay
The information you can be engaged on as a knowledge scientist received’t at all times have distinct demarcations when plotted, as you’d see on iris dataset. Oftentimes, you’ll take care of knowledge with increased dimensions that can not be plotted, or even when it’s plotted, you received’t be capable to inform the optimum variety of groupings. A very good instance of that is within the graph under.
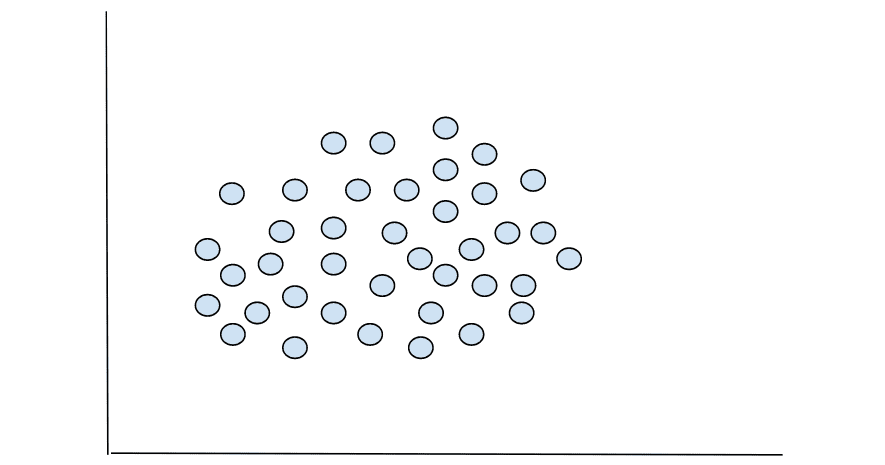
Are you able to inform the variety of groupings? Not clearly. So, how will we discover the optimum variety of clusters into which the above knowledge factors will be grouped?
There are completely different strategies used to seek out the optimum Okay, into which the information factors of a given knowledge set will be grouped, elbow and silhouette strategies. Let’s briefly take a look at how the 2 approaches work.
Elbow technique
This strategy makes use of the full variations inside a cluster, in any other case generally known as the WCSS (inside cluster sum of squares). The purpose is to have the minimal variance inside clusters (WCSS).
This technique works on this approach:
- It takes a variety of Okay values, say 1 – 8 and calculates the WSS for every Okay worth.
- The ensuing knowledge could have a Okay worth and the corresponding WSS. This knowledge is then used to plot a graph of WCSS in opposition to the okay values.
- The optimum variety of Okay is on the elbow level, the place the curve begins to speed up. It’s from this level that the strategy derives its identify. Consider the elbow of your arm.
Silhouette technique
This technique measures similarity and dissimilarity. It quantifies the space of a degree to different members of its assigned cluster, and in addition the space to the members in different clusters. It really works on this approach:
- It takes a variety of Okay values starting with 2.
- For every worth of Okay, it computes the cluster similarity, which is the common distance between a knowledge level and all different group members in the identical cluster.
- Subsequent, the cluster dissimilarity is calculated by calculating the common distance between a knowledge level and all different members of the closest cluster.
- The silhouette coefficient would be the distinction between cluster similarity worth and cluster dissimilarity worth, divided by the most important of the 2 values.
The optimum Okay could be one with the best coefficient. The values of this coefficient are bounded within the vary of -1 to 1.
That is an introductory article to Okay-Means clustering algorithm the place we’ve coated what it’s, the way it works, and the way to decide on Okay. Within the subsequent article, we’ll stroll by the method on the best way to resolve an actual world clustering issues utilizing Python’s scikit-learn library.
Clinton Oyogo Clinton believes that analyzing knowledge for actionable insights is an important a part of his day-to-day work. Together with his expertise in knowledge visualization, knowledge wrangling, and machine studying, he takes pleasure in his work as a knowledge scientist.
Original. Reposted with permission.




