Enhance multi-hop reasoning in LLMs by studying from wealthy human suggestions
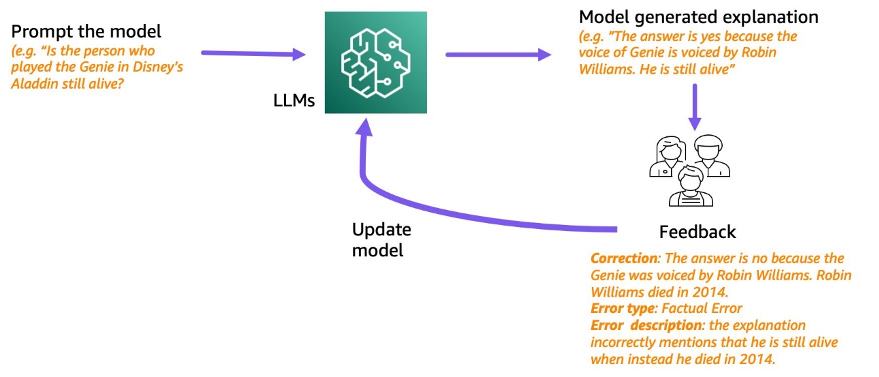
Latest massive language fashions (LLMs) have enabled super progress in pure language understanding. Nonetheless, they’re vulnerable to producing assured however nonsensical explanations, which poses a major impediment to establishing belief with customers. On this publish, we present how one can incorporate human suggestions on the inaccurate reasoning chains for multi-hop reasoning to enhance efficiency on these duties. As a substitute of gathering the reasoning chains from scratch by asking people, we as an alternative study from wealthy human suggestions on model-generated reasoning chains utilizing the prompting skills of the LLMs. We accumulate two such datasets of human suggestions within the type of (correction, rationalization, error sort) for StrategyQA and Sports activities Understanding datasets, and consider a number of frequent algorithms to study from such suggestions. Our proposed strategies carry out competitively to chain-of-thought prompting utilizing the bottom Flan-T5, and ours is healthier at judging the correctness of its personal reply.
Resolution overview
With the onset of huge language fashions, the sector has seen super progress on numerous pure language processing (NLP) benchmarks. Amongst them, the progress has been placing on comparatively easier duties similar to brief context or factual query answering, in comparison with tougher duties that require reasoning similar to multi-hop query answering. The efficiency of sure duties utilizing LLMs could also be just like random guessing at smaller scales, however improves considerably at bigger scales. Regardless of this, the prompting skills of LLMs have the potential to supply some related info required to reply the query.
Nonetheless, these fashions might not reliably generate appropriate reasoning chains or explanations. These assured however nonsensical explanations are much more prevalent when LLMs are skilled utilizing Reinforcement Studying from Human Suggestions (RLHF), the place reward hacking might happen.
Motivated by this, we attempt to deal with the next analysis query: can we enhance reasoning of LLMs by studying from human suggestions on model-generated reasoning chains? The next determine supplies an summary of our method: we first immediate the mannequin to generate reasoning chains for multi-hop questions, then accumulate various human suggestions on these chains for prognosis and suggest coaching algorithms to study from the collected information.

We accumulate various human suggestions on two multi-hop reasoning datasets, StrategyQA and Sports activities Understanding from BigBench. For every query and model-generated reasoning chain, we accumulate the proper reasoning chain, the kind of error within the model-generated reasoning chain, and an outline (in pure language) of why that error is introduced within the offered reasoning chain. The ultimate dataset comprises suggestions for 1,565 samples from StrategyQA and 796 examples for Sports activities Understanding.
We suggest a number of coaching algorithms to study from the collected suggestions. First, we suggest a variant of self-consistency in chain-of-thought prompting by contemplating a weighted variant of it that may be realized from the suggestions. Second, we suggest iterative refinement, the place we iteratively refine the model-generated reasoning chain till it’s appropriate. We reveal empirically on the 2 datasets that fine-tuning an LLM, specifically Flan-T5 utilizing the proposed algorithms, performs comparably to the in-context studying baseline. Extra importantly, we present that the fine-tuned mannequin is healthier at judging if its personal reply is appropriate in comparison with the bottom Flan-T5 mannequin.
Information assortment
On this part, we describe the small print of the suggestions we collected and the annotation protocol adopted throughout information assortment. We collected suggestions for mannequin generations primarily based on two reasoning-based datasets: StrategyQA and Sports activities Understanding from BigBench. We used GPT-J to generate the reply for StrategyQA and Flan-T5 to generate the reply for the Sports activities Understanding dataset. In every case, the mannequin was prompted with ok in-context examples containing query, reply, and rationalization, adopted by the check query.
The next determine reveals the interface we used. Annotators are given the query, the model-generated reply, and the reason break up into steps.

For every query, we collected the next suggestions:
- Subquestions – The annotators decompose the unique query into easier subquestions required to reply the unique query. This activity was added after a pilot the place we discovered that including this activity helps put together the annotators and enhance the standard of the remainder of the duties.
- Correction – Annotators are supplied with a free-form textual content field pre-filled with the model-generated reply and rationalization, and requested to edit it to acquire the proper reply and rationalization.
- Error sort – Among the many most typical kinds of error we discovered within the mannequin generations (Factual Error, Lacking Information, Irrelevant Information, and Logical Inconsistency), annotators have been requested to choose a number of of the error varieties that apply to the given reply and rationalization.
- Error description – The annotators have been instructed to not solely classify the errors but additionally give a complete justification for his or her categorization, together with pinpointing the precise step the place the error occurred and the way it applies to the reply and rationalization offered.
We used Amazon SageMaker Ground Truth Plus in our information assortment. The info assortment came about over a number of rounds. We first carried out two small pilots of 30 examples and 200 examples, respectively, after which the annotator workforce was given detailed suggestions on the annotation. We then carried out the info assortment over two batches for StrategyQA, and over one batch for Sports activities Understanding, giving periodic suggestions all through—a complete of 10 annotators labored on the duty over a interval of near 1 month.
We gathered suggestions on a complete of 1,565 examples for StrategyQA and 796 examples for Sports activities Understanding. The next desk illustrates the share of examples that have been error-free within the mannequin technology and the proportion of examples that contained a selected error sort. It’s price noting that some examples might have multiple error sort.
| Error Sort | StrategyQA | Sports activities Understanding |
| None | 17.6% | 31.28% |
| Factual Error | 27.6% | 38.1% |
| Lacking Information | 50.4% | 46.1% |
| Irrelevant Information | 14.6% | 3.9% |
| Logical Inconsistency | 11.2% | 5.2% |
Studying algorithms
For every query q, and model-generated reply and rationalization m, we collected the next suggestions: appropriate reply and rationalization c, sort of error current in m (denoted by t), and error description d, as described within the earlier part.
We used the next strategies:
- Multitask studying – A easy baseline to study from the varied suggestions obtainable is to deal with every of them as a separate activity. Extra concretely, we fine-tune Flan-T5 (textual content to textual content) with the target maximize p(c|q) + p(t|q, m) + p(d|q, m). For every time period within the goal, we use a separate instruction acceptable for the duty (for instance, “Predict error within the given reply”). We additionally convert the specific variable t right into a pure language sentence. Throughout inference, we use the instruction for the time period p(c|q) (“Predict the proper reply for the given query”) to generate the reply for the check query.
- Weighted self-consistency – Motivated by the success of self-consistency in chain-of-thought prompting, we suggest a weighted variant of it. As a substitute of treating every sampled rationalization from the mannequin as appropriate and contemplating the combination vote, we as an alternative first think about whether or not the reason is appropriate after which combination accordingly. We first fine-tune Flan-T5 with the identical goal as in multitask studying. Throughout inference, given a check query q, we pattern a number of doable solutions with the instruction for p(c|q)): a1, a2, .., an. For every sampled reply ai, we use the instruction for the time period p(t|q, m) (“Predict error within the given reply”) to establish if it comprises error ti = argmax p(t|q, a_i). Every reply ai is assigned a weight of 1 if it’s appropriate, in any other case it’s assigned a weight smaller than 1 (tunable hyperparameter). The ultimate reply is obtained by contemplating a weighted vote over all of the solutions a1 to an.
- Iterative refinement – Within the earlier proposed strategies, the mannequin immediately generates the proper reply c conditioned on the query q. Right here we suggest to refine the model-generated reply m to acquire the proper reply for a given query. Extra particularly, we first fine-tune Flan-T5 (textual content to textual content with the target) with maximize p(t; c|q, m), the place ; denotes the concatenation (error sort t adopted by the proper reply c). One solution to view this goal is that the mannequin is first skilled to establish the error in given technology m, after which to take away that error to acquire the proper reply c. Throughout inference, we will use the mannequin iteratively till it generates the proper reply—given a check query q, we first receive the preliminary mannequin technology m (utilizing pre-trained Flan-T5). We then iteratively generate the error sort ti and potential appropriate reply ci till ti = no error (in follow, we set a most variety of iterations to a hyperparameter), during which case the ultimate appropriate reply shall be ci-1 (obtained from p(ti ; ci | q, ci-1)).
Outcomes
For each datasets, we examine all of the proposed studying algorithms with the in-context studying baseline. All fashions are evaluated on the dev set of StrategyQA and Sports activities Understanding. The next desk reveals the outcomes.
| Methodology | StrategyQA | Sports activities Understanding |
| Flan-T5 4-shot Chain-of-Thought In-Context Studying | 67.39 ± 2.6% | 58.5% |
| Multitask Studying | 66.22 ± 0.7% | 54.3 ± 2.1% |
| Weighted Self Consistency | 61.13 ± 1.5% | 51.3 ± 1.9% |
| Iterative Refinement | 61.85 ± 3.3% | 57.0 ± 2.5% |
As noticed, some strategies carry out similar to the in-context studying baseline (multitask for StrategyQA, and iterative refinement for Sports activities Understanding), which demonstrates the potential of gathering ongoing suggestions from people on mannequin outputs and utilizing that to enhance language fashions. That is totally different from latest work similar to RLHF, the place the suggestions is proscribed to categorical and normally binary.
As proven within the following desk, we examine how fashions tailored with human suggestions on reasoning errors can assist enhance the calibration or the attention of confidently improper explanations. That is evaluated by prompting the mannequin to foretell if its technology comprises any errors.
| Methodology | Error Correction | StrategyQA |
| Flan-T5 4-shot Chain-of-Thought In-Context Studying | No | 30.17% |
| Multitask Finetuned Mannequin | Sure | 73.98% |
In additional element, we immediate the language mannequin with its personal generated reply and reasoning chain (for which we collected suggestions), after which immediate it once more to foretell the error within the technology. We use the suitable instruction for the duty (“Determine error within the reply”). The mannequin is scored appropriately if it predicts “no error” or “appropriate” within the technology if the annotators labeled the instance as having no error, or if it predicts any of the error varieties within the technology (together with “incorrect” or “improper”) when the annotators labeled it as having an error. Word that we don’t consider the mannequin’s skill to appropriately establish the error sort, however reasonably if an error is current. The analysis is finished on a set of 173 extra examples from the StrategyQA dev set that have been collected, which aren’t seen throughout fine-tuning. 4 examples out of those are reserved for prompting the language mannequin (first row within the previous desk).
Word that we don’t present the 0-shot baseline consequence as a result of the mannequin is unable to generate helpful responses. We observe that utilizing human suggestions for error correction on reasoning chains can enhance the mannequin’s prediction of whether or not it makes errors or not, which might enhance the attention or calibration of the improper explanations.
Conclusion
On this publish, we confirmed how one can curate human suggestions datasets with fine-grained error corrections, which is an alternate means to enhance the reasoning skills of LLMs. Experimental outcomes corroborate that human suggestions on reasoning errors can enhance efficiency and calibration on difficult multi-hop questions.
Should you’re on the lookout for human suggestions to enhance your massive language fashions, go to Amazon SageMaker Data Labeling and the Floor Reality Plus console.
In regards to the Authors
 Erran Li is the utilized science supervisor at humain-in-the-loop companies, AWS AI, Amazon. His analysis pursuits are 3D deep studying, and imaginative and prescient and language illustration studying. Beforehand he was a senior scientist at Alexa AI, the top of machine studying at Scale AI and the chief scientist at Pony.ai. Earlier than that, he was with the notion workforce at Uber ATG and the machine studying platform workforce at Uber engaged on machine studying for autonomous driving, machine studying techniques and strategic initiatives of AI. He began his profession at Bell Labs and was adjunct professor at Columbia College. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized a number of workshops at NeurIPS, ICML, CVPR, ICCV on machine studying for autonomous driving, 3D imaginative and prescient and robotics, machine studying techniques and adversarial machine studying. He has a PhD in laptop science at Cornell College. He’s an ACM Fellow and IEEE Fellow.
Erran Li is the utilized science supervisor at humain-in-the-loop companies, AWS AI, Amazon. His analysis pursuits are 3D deep studying, and imaginative and prescient and language illustration studying. Beforehand he was a senior scientist at Alexa AI, the top of machine studying at Scale AI and the chief scientist at Pony.ai. Earlier than that, he was with the notion workforce at Uber ATG and the machine studying platform workforce at Uber engaged on machine studying for autonomous driving, machine studying techniques and strategic initiatives of AI. He began his profession at Bell Labs and was adjunct professor at Columbia College. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized a number of workshops at NeurIPS, ICML, CVPR, ICCV on machine studying for autonomous driving, 3D imaginative and prescient and robotics, machine studying techniques and adversarial machine studying. He has a PhD in laptop science at Cornell College. He’s an ACM Fellow and IEEE Fellow.
 Nitish Joshi was an utilized science intern at AWS AI, Amazon. He’s a PhD pupil in laptop science at New York College’s Courant Institute of Mathematical Sciences suggested by Prof. He He. He works on Machine Studying and Pure Language Processing, and he was affiliated with the Machine Studying for Language (ML2) analysis group. He was broadly all for strong language understanding: each in constructing fashions that are strong to distribution shifts (e.g. by way of human-in-the-loop information augmentation) and likewise in designing higher methods to guage/measure the robustness of fashions. He has additionally been curious in regards to the latest developments in in-context studying and understanding the way it works.
Nitish Joshi was an utilized science intern at AWS AI, Amazon. He’s a PhD pupil in laptop science at New York College’s Courant Institute of Mathematical Sciences suggested by Prof. He He. He works on Machine Studying and Pure Language Processing, and he was affiliated with the Machine Studying for Language (ML2) analysis group. He was broadly all for strong language understanding: each in constructing fashions that are strong to distribution shifts (e.g. by way of human-in-the-loop information augmentation) and likewise in designing higher methods to guage/measure the robustness of fashions. He has additionally been curious in regards to the latest developments in in-context studying and understanding the way it works.
 Kumar Chellapilla is a Normal Supervisor and Director at Amazon Internet Providers and leads the event of ML/AI Providers similar to human-in-loop techniques, AI DevOps, Geospatial ML, and ADAS/Autonomous Car growth. Previous to AWS, Kumar was a Director of Engineering at Uber ATG and Lyft Stage 5 and led groups utilizing machine studying to develop self-driving capabilities similar to notion and mapping. He additionally labored on making use of machine studying strategies to enhance search, suggestions, and promoting merchandise at LinkedIn, Twitter, Bing, and Microsoft Analysis.
Kumar Chellapilla is a Normal Supervisor and Director at Amazon Internet Providers and leads the event of ML/AI Providers similar to human-in-loop techniques, AI DevOps, Geospatial ML, and ADAS/Autonomous Car growth. Previous to AWS, Kumar was a Director of Engineering at Uber ATG and Lyft Stage 5 and led groups utilizing machine studying to develop self-driving capabilities similar to notion and mapping. He additionally labored on making use of machine studying strategies to enhance search, suggestions, and promoting merchandise at LinkedIn, Twitter, Bing, and Microsoft Analysis.





