Decoding the Impression of Suggestions Protocols on Giant Language Mannequin Alignment: Insights from Scores vs. Rankings
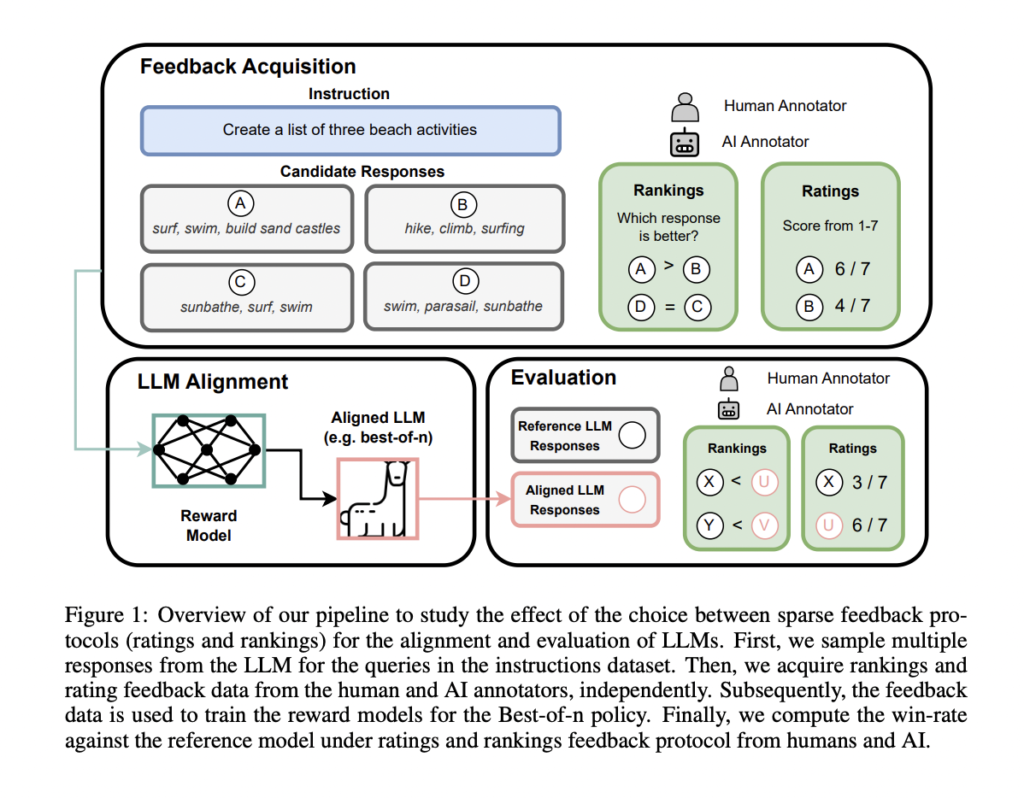
Alignment has develop into a pivotal concern for the event of next-generation text-based assistants, significantly in guaranteeing that enormous language fashions (LLMs) align with human values. This alignment goals to reinforce LLM-generated content material’s accuracy, coherence, and harmlessness in response to person queries. The alignment course of contains three key components: suggestions acquisition, alignment algorithms, and mannequin analysis. Whereas earlier efforts targeted on alignment algorithms, this examine delves into the nuances of suggestions acquisition, particularly evaluating scores and rankings protocols, shedding mild on a major consistency problem.
In present literature, alignment algorithms similar to PPO, DPO, and PRO have been extensively explored below particular suggestions protocols and analysis setups. In the meantime, suggestions acquisition methods have focused on growing fine-grained and dense protocols, which will be difficult and dear. This examine analyzes the influence of two suggestions protocols, scores and rankings, on LLM alignment. Determine 1 supplies an illustration of their pipeline.

Understanding Suggestions Protocols: Scores vs. Rankings
Scores contain assigning an absolute worth to a response utilizing a predefined scale, whereas rankings require annotators to pick their most well-liked response from a pair. Scores quantify response goodness however will be difficult for complicated directions, whereas rankings are simpler for such directions however lack quantification of the hole between responses (Listed in Desk 1).
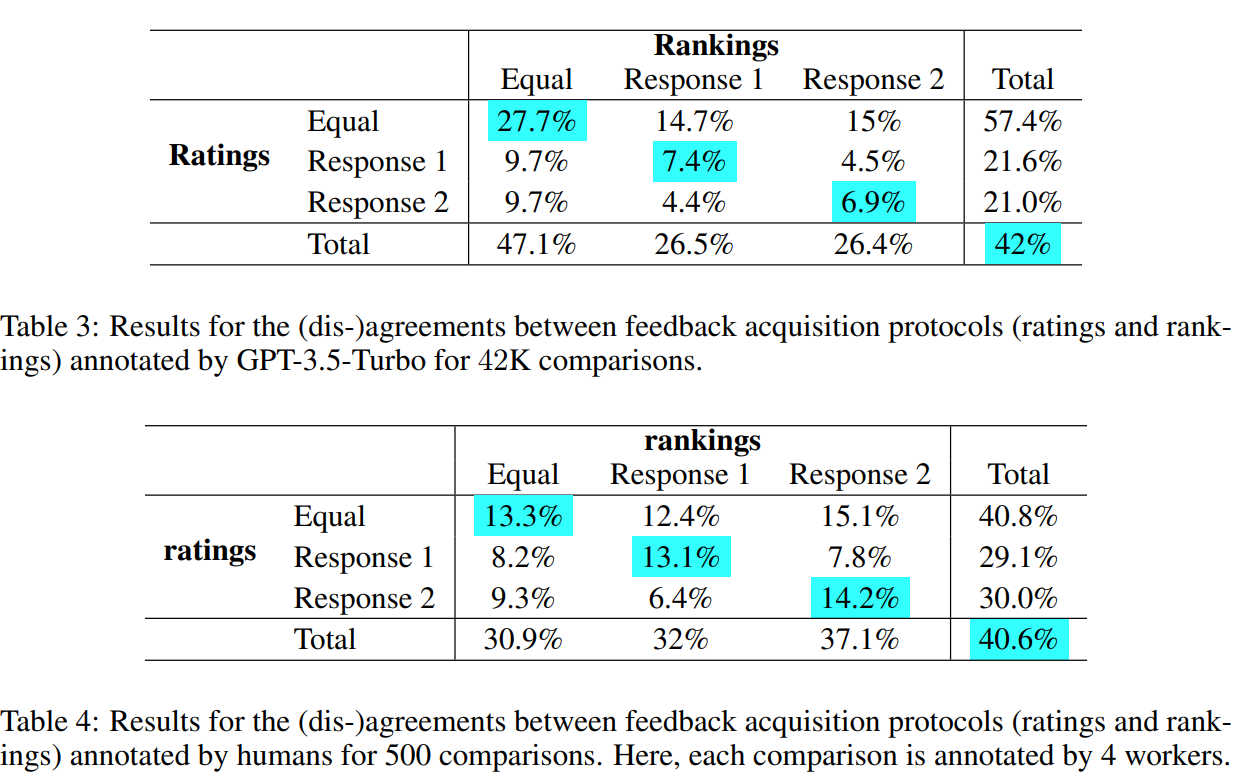
Now we are going to delve deeper into the initially introduced suggestions inconsistency drawback. The authors make use of the remark that the scores on a pair of responses for a given instruction will be in comparison with convert the scores suggestions knowledge into its rankings type. This conversion of the scores knowledge DA to the rankings knowledge DRA permits us a novel alternative to review the interaction between absolutely the suggestions DA and relative suggestions DR collected from the annotators, independently. Right here, they outline the time period consistency because the settlement between the scores (transformed to its rankings type) and the rankings acquired by a pair of responses to a given instruction impartial of the scores knowledge.
We will clearly observe consistency points from Desk 3 and 4 in each human and AI suggestions knowledge. Curiously, the consistency rating falls inside an identical vary of 40% − 42% for each people and AI, suggesting {that a} substantial portion of the suggestions knowledge can yield contradictory preferences relying on the suggestions protocol employed. This consistency drawback underscores a number of essential factors: (a) it signifies variations within the perceived high quality of responses based mostly on the selection of the suggestions acquisition protocols, (b) it underscores that the alignment pipeline can fluctuate considerably relying on whether or not scores or rankings are used as sparse types of suggestions, and (c) it emphasizes the need of meticulous knowledge curation when working with a number of suggestions protocols for aligning LLMs.
Exploring Suggestions Inconsistency:
The examine delves into the recognized suggestions inconsistency drawback, leveraging an insightful remark. By evaluating scores on a pair of responses, the authors convert score suggestions knowledge (DA) into rankings knowledge (DRA). This conversion provides a novel alternative to independently examine the interaction between absolute suggestions (DA) and relative suggestions (DR) from annotators. Consistency, outlined because the settlement between transformed scores and unique rankings, is assessed. Notably, Tables 3 and 4 reveal constant points in each human and AI suggestions, with a noteworthy consistency rating vary of 40%−42%. This underscores variations in perceived response high quality based mostly on suggestions acquisition protocols, highlighting the numerous influence on the alignment pipeline and emphasizing the necessity for meticulous knowledge curation when dealing with various suggestions protocols in aligning LLMs.
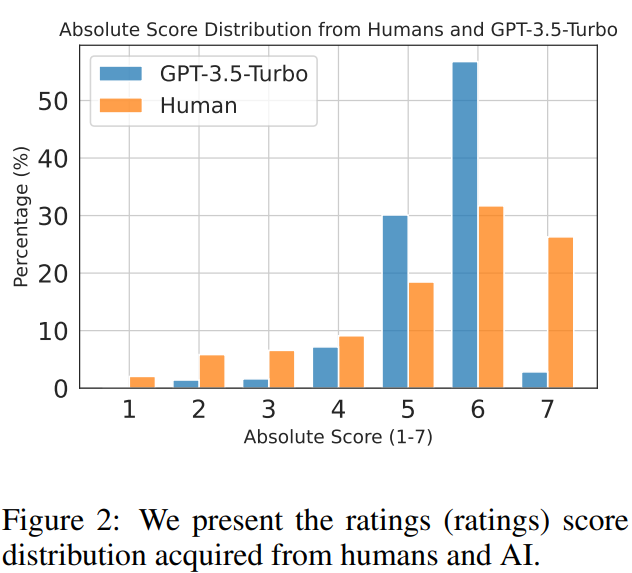
Suggestions Knowledge Acquisition
The examine makes use of various directions from sources like Dolly, Self-Instruct, and Tremendous-NI to gather suggestions. Alpaca-7B serves as the bottom LLM, producing candidate responses for analysis. The authors leverage GPT-3.5-Turbo for large-scale scores and rankings suggestions knowledge assortment. Additionally they gather suggestions knowledge below the scores and rankings protocols.
Evaluation of score distribution (proven in Determine 2) signifies human annotators have a tendency to provide greater scores, whereas AI suggestions is extra balanced. The examine additionally ensures suggestions knowledge is unbiased in direction of longer or distinctive responses. Settlement evaluation (proven in Desk 2) between human-human and human-AI suggestions reveals affordable alignment charges. In abstract, the settlement outcomes point out that GPT-3.5-Turbo can present scores and rankings suggestions near the human’s gold label for the responses to the directions in our dataset.
Impression on Alignment and Mannequin Analysis
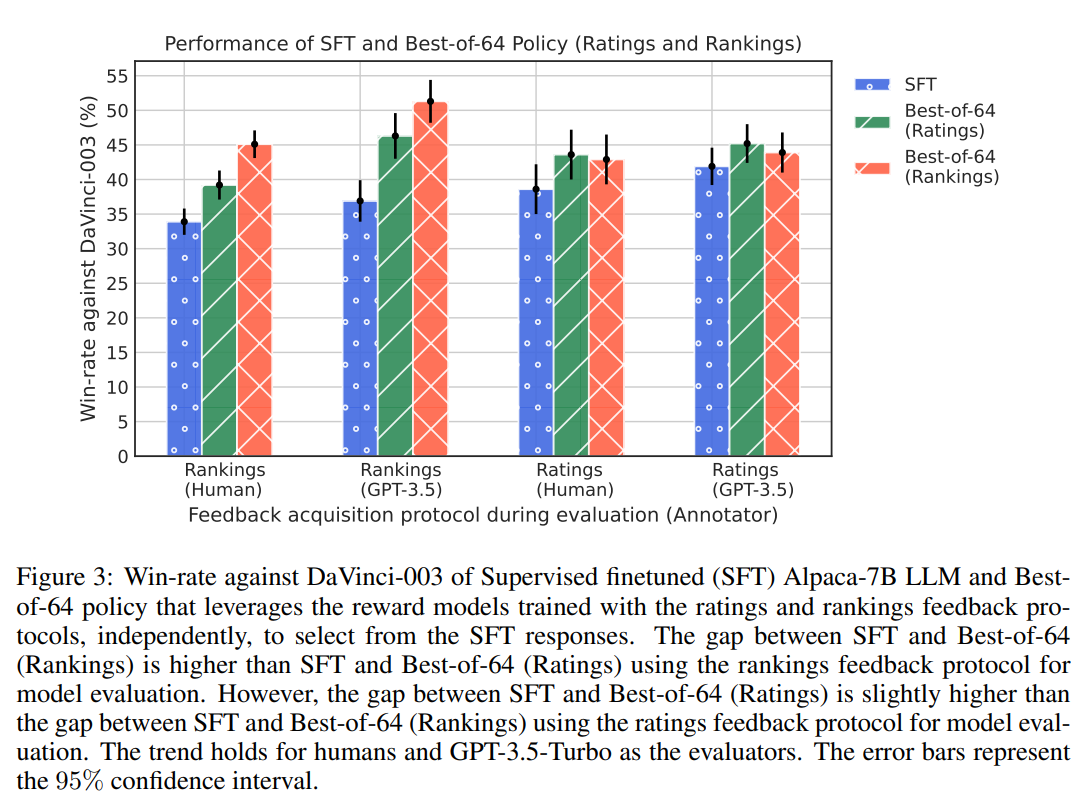
The examine trains reward fashions based mostly on scores and rankings suggestions and assesses Greatest-of-n insurance policies. Analysis on unseen directions reveals Greatest-of-n insurance policies, particularly with rankings suggestions, outperform the bottom LLM (SFT) and show enchancment in alignment (proven in Determine 3).
A shocking revelation within the examine unveils an analysis inconsistency phenomenon, the place the suggestions protocol alternative throughout analysis appears to favor the alignment algorithm that aligns with the identical suggestions protocol. Notably, the hole in win charges between the Greatest-of-n (rankings) coverage and the SFT is extra pronounced (11.2%) than the hole noticed between the Greatest-of-n (scores) coverage and SFT (5.3%) below the rankings protocol. Conversely, below the scores protocol, the hole between the Greatest-of-n (scores) coverage and SFT (5%) barely outweighs the hole between the Greatest-of-n (rankings) coverage and SFT (4.3%). This inconsistency extends to evaluations involving GPT-3.5-Turbo, indicating a nuanced notion of coverage response high quality by annotators (each human and AI) below distinct suggestions protocols. These findings underscore the substantial implications for practitioners, highlighting that the suggestions acquisition protocol considerably influences every stage of the alignment pipeline.
In conclusion, The examine underscores the paramount significance of meticulous knowledge curation inside sparse suggestions protocols, shedding mild on the potential repercussions of suggestions protocol decisions on analysis outcomes. Within the pursuit of mannequin alignment, future analysis avenues might delve into the cognitive features of the recognized consistency drawback, aiming to reinforce alignment methods. Exploring richer types of suggestions past the scope of absolute and relative preferences is essential for a extra complete understanding and improved alignment in various software domains. Regardless of its precious insights, the examine acknowledges limitations, together with its deal with particular sorts of suggestions, potential subjectivity in human annotations, and the need to discover the influence on totally different demographic teams and specialised domains. Addressing these limitations will contribute to growing extra sturdy and universally relevant alignment methodologies within the evolving panorama of synthetic intelligence.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the most recent developments in Deep Studying, Pc Imaginative and prescient, and associated fields.





