Improve Amazon Lex with LLMs and enhance the FAQ expertise utilizing URL ingestion

In in the present day’s digital world, most customers would reasonably discover solutions to their customer support questions on their very own reasonably than taking the time to succeed in out to companies and/or service suppliers. This weblog publish explores an revolutionary answer to construct a query and reply chatbot in Amazon Lex that makes use of current FAQs out of your web site. This AI-powered software can present fast, correct responses to real-world inquiries, permitting the shopper to rapidly and simply clear up widespread issues independently.
Single URL ingestion
Many enterprises have a broadcast set of solutions for FAQs for his or her prospects out there on their web site. On this case, we wish to supply prospects a chatbot that may reply their questions from our printed FAQs. Within the weblog publish titled Enhance Amazon Lex with conversational FAQ features using LLMs, we demonstrated how you should use a mix of Amazon Lex and LlamaIndex to construct a chatbot powered by your current data sources, equivalent to PDF or Phrase paperwork. To assist a easy FAQ, based mostly on a web site of FAQs, we have to create an ingestion course of that may crawl the web site and create embeddings that can be utilized by LlamaIndex to reply buyer questions. On this case, we’ll construct on the bot created within the previous blog post, which queries these embeddings with a person’s utterance and returns the reply from the web site FAQs.
The next diagram reveals how the ingestion course of and the Amazon Lex bot work collectively for our answer.
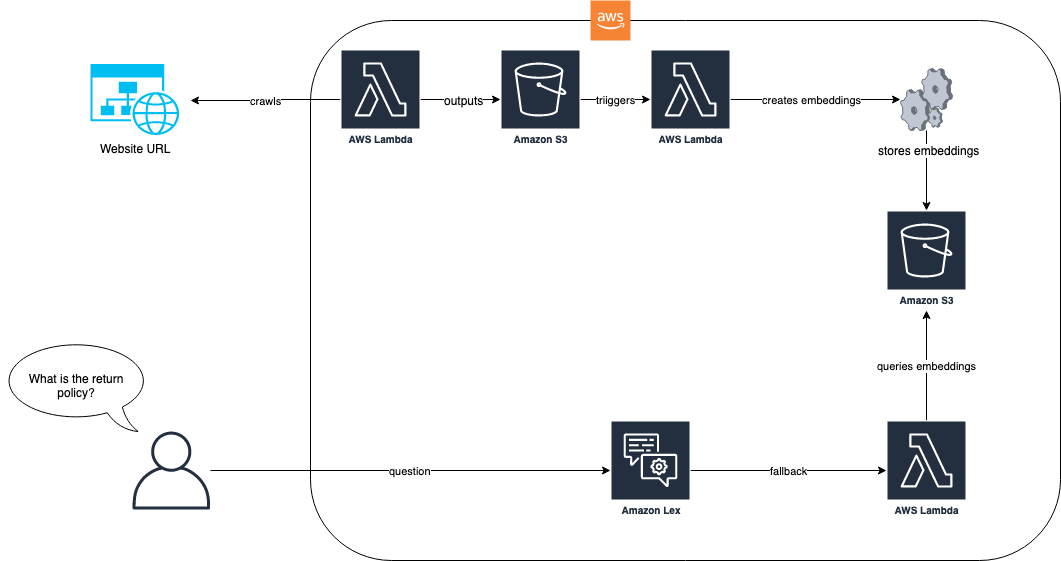
Within the answer workflow, the web site with FAQs is ingested through AWS Lambda. This Lambda operate crawls the web site and shops the ensuing textual content in an Amazon Simple Storage Service (Amazon S3) bucket. The S3 bucket then triggers a Lambda operate that makes use of LlamaIndex to create embeddings which can be saved in Amazon S3. When a query from an end-user arrives, equivalent to “What’s your return coverage?”, the Amazon Lex bot makes use of its Lambda operate to question the embeddings utilizing a RAG-based strategy with LlamaIndex. For extra details about this strategy and the pre-requisites, check with the weblog publish, Enhance Amazon Lex with conversational FAQ features using LLMs.
After the pre-requisites from the aforementioned weblog are full, step one is to ingest the FAQs right into a doc repository that may be vectorized and listed by LlamaIndex. The next code reveals the best way to accomplish this:
Within the previous instance, we take a predefined FAQ web site URL from Zappos and ingest it utilizing the EZWebLoader class. With this class, we have now navigated to the URL and loaded all of the questions which can be within the web page into an index. We are able to now ask a query like “Does Zappos have present playing cards?” and get the solutions instantly from our FAQs on the web site. The next screenshot reveals the Amazon Lex bot take a look at console answering that query from the FAQs.

We had been capable of obtain this as a result of we had crawled the URL in step one and created embedddings that LlamaIndex may use to seek for the reply to our query. Our bot’s Lambda operate reveals how this search is run at any time when the fallback intent is returned:
This answer works effectively when a single webpage has all of the solutions. Nonetheless, most FAQ websites should not constructed on a single web page. As an example, in our Zappos instance, if we ask the query “Do you might have a value matching coverage?”, then we get a less-than-satisfactory reply, as proven within the following screenshot.
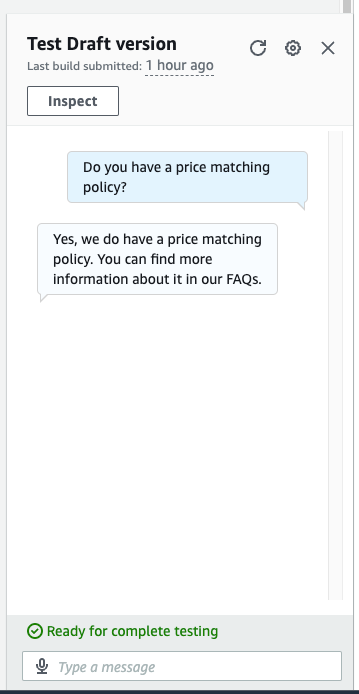
Within the previous interplay, the price-matching coverage reply isn’t useful for our person. This reply is brief as a result of the FAQ referenced is a hyperlink to a selected web page concerning the value matching coverage and our internet crawl was just for the one web page. Reaching higher solutions will imply crawling these hyperlinks as effectively. The following part reveals the best way to get solutions to questions that require two or extra ranges of web page depth.
N-level crawling
After we crawl an internet web page for FAQ data, the knowledge we wish may be contained in linked pages. For instance, in our Zappos instance, we ask the query “Do you might have a value matching coverage?” and the reply is “Sure please go to <hyperlink> to be taught extra.” If somebody asks “What’s your value matching coverage?” then we wish to give an entire reply with the coverage. Reaching this implies we have now the necessity to traverse hyperlinks to get the precise info for our end-user. Throughout the ingestion course of, we are able to use our internet loader to search out the anchor hyperlinks to different HTML pages after which traverse them. The next code change to our internet crawler permits us to search out hyperlinks within the pages we crawl. It additionally consists of some further logic to keep away from round crawling and permit a filter by a prefix.
Within the previous code, we introduce the flexibility to crawl N ranges deep, and we give a prefix that enables us to limit crawling to solely issues that start with a sure URL sample. In our Zappos instance, the customer support pages all are rooted from zappos.com/c, so we embody that as a prefix to restrict our crawls to a smaller and extra related subset. The code reveals how we are able to ingest as much as two ranges deep. Our bot’s Lambda logic stays the identical as a result of nothing has modified besides the crawler ingests extra paperwork.
We now have all of the paperwork listed and we are able to ask a extra detailed query. Within the following screenshot, our bot gives the right reply to the query “Do you might have a value matching coverage?”

We now have an entire reply to our query about value matching. As a substitute of merely being instructed “Sure see our coverage,” it offers us the small print from the second-level crawl.
Clear up
To keep away from incurring future bills, proceed with deleting all of the sources that had been deployed as a part of this train. We now have offered a script to close down the Sagemaker endpoint gracefully. Utilization particulars are within the README. Moreover, to take away all the opposite sources you’ll be able to run cdk destroy in the identical listing as the opposite cdk instructions to deprovision all of the sources in your stack.
Conclusion
The power to ingest a set of FAQs right into a chatbot permits your prospects to search out the solutions to their questions with simple, pure language queries. By combining the built-in assist in Amazon Lex for fallback dealing with with a RAG answer equivalent to a LlamaIndex, we are able to present a fast path for our prospects to get satisfying, curated, and permitted solutions to FAQs. By making use of N-level crawling into our answer, we are able to permit for solutions that would probably span a number of FAQ hyperlinks and supply deeper solutions to our buyer’s queries. By following these steps, you’ll be able to seamlessly incorporate highly effective LLM-based Q and A capabilities and environment friendly URL ingestion into your Amazon Lex chatbot. This ends in extra correct, complete, and contextually conscious interactions with customers.
In regards to the authors
 Max Henkel-Wallace is a Software program Improvement Engineer at AWS Lex. He enjoys working leveraging know-how to maximise buyer success. Outdoors of labor he’s keen about cooking, spending time with buddies, and backpacking.
Max Henkel-Wallace is a Software program Improvement Engineer at AWS Lex. He enjoys working leveraging know-how to maximise buyer success. Outdoors of labor he’s keen about cooking, spending time with buddies, and backpacking.
 Tune Feng is a Senior Utilized Scientist at AWS AI Labs, specializing in Pure Language Processing and Synthetic Intelligence. Her analysis explores numerous facets of those fields together with document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive textual content era utilizing multimodal information.
Tune Feng is a Senior Utilized Scientist at AWS AI Labs, specializing in Pure Language Processing and Synthetic Intelligence. Her analysis explores numerous facets of those fields together with document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive textual content era utilizing multimodal information.
 John Baker is a Principal SDE at AWS the place he works on Pure Language Processing, Giant Language Fashions and different ML/AI associated initiatives. He has been with Amazon for 9+ years and has labored throughout AWS, Alexa and Amazon.com. In his spare time, John enjoys snowboarding and different outside actions all through the Pacific Northwest.
John Baker is a Principal SDE at AWS the place he works on Pure Language Processing, Giant Language Fashions and different ML/AI associated initiatives. He has been with Amazon for 9+ years and has labored throughout AWS, Alexa and Amazon.com. In his spare time, John enjoys snowboarding and different outside actions all through the Pacific Northwest.




