UC Berkeley And MIT Researchers Suggest A Coverage Gradient Algorithm Referred to as Denoising Diffusion Coverage Optimization (DDPO) That Can Optimize A Diffusion Mannequin For Downstream Duties Utilizing Solely A Black-Field Reward Operate
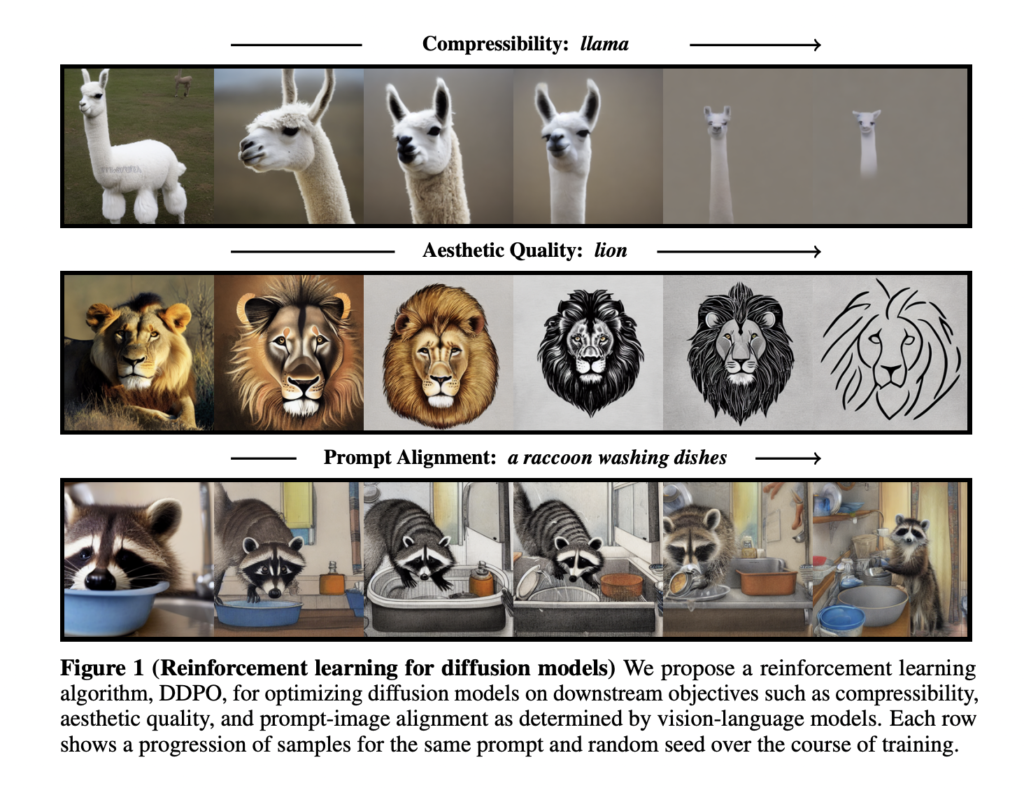
Researchers have made notable strides in coaching diffusion fashions utilizing reinforcement studying (RL) to boost prompt-image alignment and optimize numerous goals. Introducing denoising diffusion coverage optimization (DDPO), which treats denoising diffusion as a multi-step decision-making drawback, allows fine-tuning Steady Diffusion on difficult downstream goals.
By immediately coaching diffusion fashions on RL-based goals, the researchers reveal important enhancements in prompt-image alignment and optimizing goals which might be troublesome to specific by conventional prompting strategies. DDPO presents a category of coverage gradient algorithms designed for this goal. To enhance prompt-image alignment, the analysis crew incorporates suggestions from a big vision-language mannequin generally known as LLaVA. By leveraging RL coaching, they achieved outstanding progress in aligning prompts with generated photographs. Notably, the fashions shift in the direction of a extra cartoon-like model, probably influenced by the prevalence of such representations within the pretraining information.
The outcomes obtained utilizing DDPO for numerous reward features are promising. Evaluations on goals corresponding to compressibility, incompressibility, and aesthetic high quality present notable enhancements in comparison with the bottom mannequin. The researchers additionally spotlight the generalization capabilities of the RL-trained fashions, which prolong to unseen animals, on a regular basis objects, and novel mixtures of actions and objects. Whereas RL coaching brings substantial advantages, the researchers observe the potential problem of over-optimization. Nice-tuning discovered reward features can result in fashions exploiting the rewards non-usefully, usually destroying significant picture content material.
Moreover, the researchers observe a susceptibility of the LLaVA mannequin to typographic assaults. RL-trained fashions can loosely generate textual content resembling the proper variety of animals, fooling LLaVA in prompt-based alignment eventualities.
In abstract, introducing DDPO and utilizing RL coaching for diffusion fashions characterize important progress in bettering prompt-image alignment and optimizing numerous goals. The outcomes showcase developments in compressibility, incompressibility, and aesthetic high quality. Nonetheless, challenges corresponding to reward over-optimization and vulnerabilities in prompt-based alignment strategies warrant additional investigation. These findings open up new alternatives for analysis and improvement in diffusion fashions, notably in picture technology and completion duties.
Take a look at the Paper, Project, and GitHub Link. Don’t overlook to affix our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. You probably have any questions relating to the above article or if we missed something, be happy to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a 3rd yr undergraduate, presently pursuing her B.Tech from Indian Institute of Know-how(IIT), Kharagpur. She is a extremely enthusiastic particular person with a eager curiosity in Machine studying, Knowledge science and AI and an avid reader of the most recent developments in these fields.





