Dolly 2.0: ChatGPT Open Supply Various for Industrial Use


Picture from Creator | Bing Picture Creator
Dolly 2.0 is an open-source, instruction-followed, massive language mannequin (LLM) that was fine-tuned on a human-generated dataset. It may be used for each analysis and business functions.
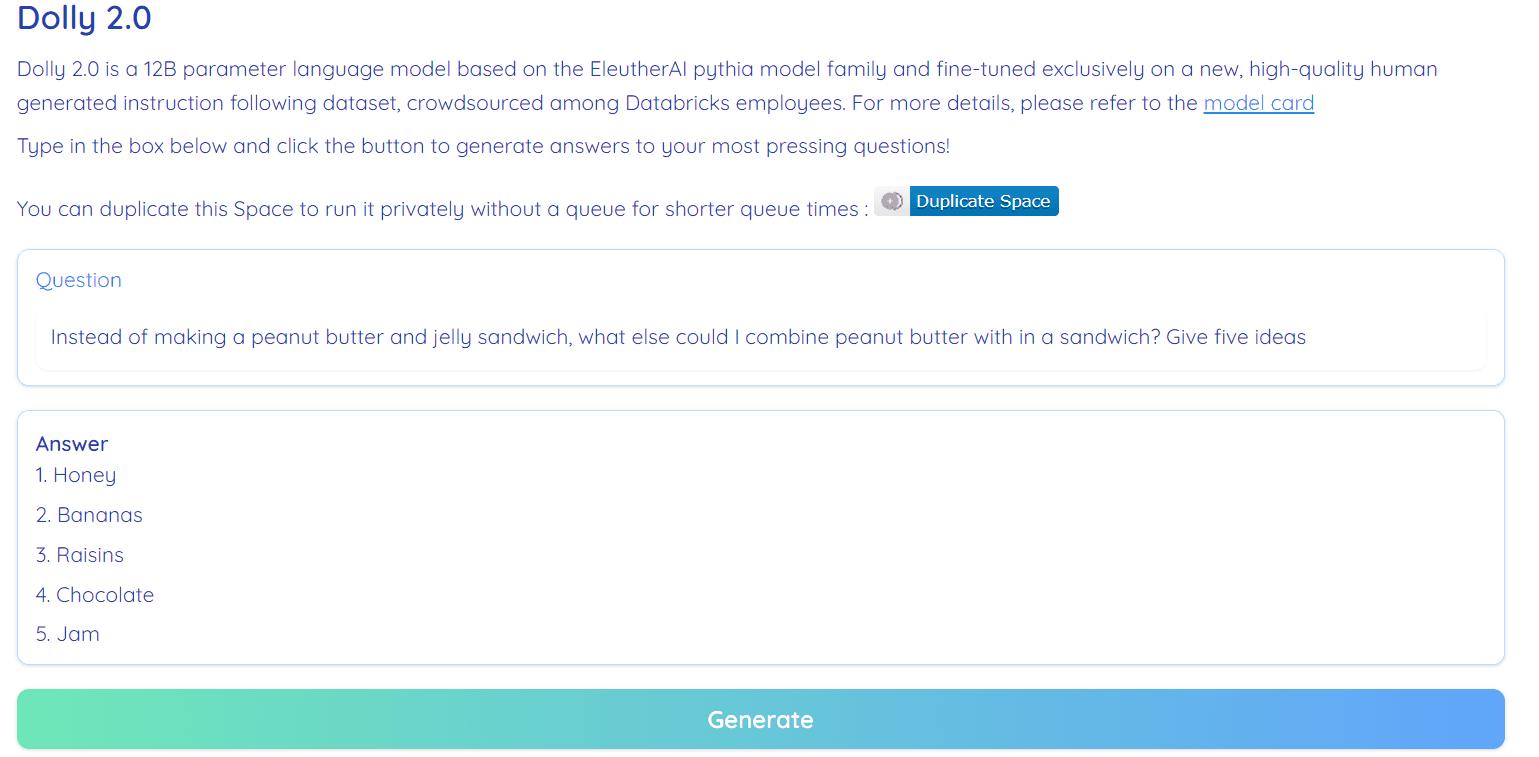
Picture from Hugging Face Space by RamAnanth1
Beforehand, the Databricks staff launched Dolly 1.0, LLM, which reveals ChatGPT-like instruction following capacity and prices lower than $30 to coach. It was utilizing the Stanford Alpaca staff dataset, which was below a restricted license (Analysis solely).
Dolly 2.0 has resolved this challenge by fine-tuning the 12B parameter language mannequin (Pythia) on a high-quality human-generated instruction within the following dataset, which was labeled by a Datbricks worker. Each mannequin and dataset can be found for business use.
Dolly 1.0 was educated on a Stanford Alpaca dataset, which was created utilizing OpenAI API. The dataset incorporates the output from ChatGPT and prevents anybody from utilizing it to compete with OpenAI. In brief, you can’t construct a business chatbot or language software based mostly on this dataset.
A lot of the newest fashions launched in the previous few weeks suffered from the identical points, fashions like Alpaca, Koala, GPT4All, and Vicuna. To get round, we have to create new high-quality datasets that can be utilized for business use, and that’s what the Databricks staff has executed with the databricks-dolly-15k dataset.
The brand new dataset incorporates 15,000 high-quality human-labeled immediate/response pairs that can be utilized to design instruction tuning massive language fashions. The databricks-dolly-15k dataset comes with Creative Commons Attribution-ShareAlike 3.0 Unported License, which permits anybody to make use of it, modify it, and create a business software on it.
How did they create the databricks-dolly-15k dataset?
The OpenAI analysis paper states that the unique InstructGPT mannequin was educated on 13,000 prompts and responses. By utilizing this info, the Databricks staff began to work on it, and it seems that producing 13k questions and solutions was a tough job. They can not use artificial knowledge or AI generative knowledge, and so they should generate authentic solutions to each query. That is the place they’ve determined to make use of 5,000 workers of Databricks to create human-generated knowledge.
The Databricks have arrange a contest, wherein the highest 20 labelers would get an enormous award. On this contest, 5,000 Databricks workers participated that have been very all in favour of LLMs
The dolly-v2-12b will not be a state-of-the-art mannequin. It underperforms dolly-v1-6b in some analysis benchmarks. It could be because of the composition and dimension of the underlying fine-tuning datasets. The Dolly mannequin household is below lively growth, so that you would possibly see an up to date model with higher efficiency sooner or later.
In brief, the dolly-v2-12b mannequin has carried out higher than EleutherAI/gpt-neox-20b and EleutherAI/pythia-6.9b.

Picture from Free Dolly
Dolly 2.0 is 100% open-source. It comes with coaching code, dataset, mannequin weights, and inference pipeline. All the elements are appropriate for business use. You possibly can check out the mannequin on Hugging Face Areas Dolly V2 by RamAnanth1.
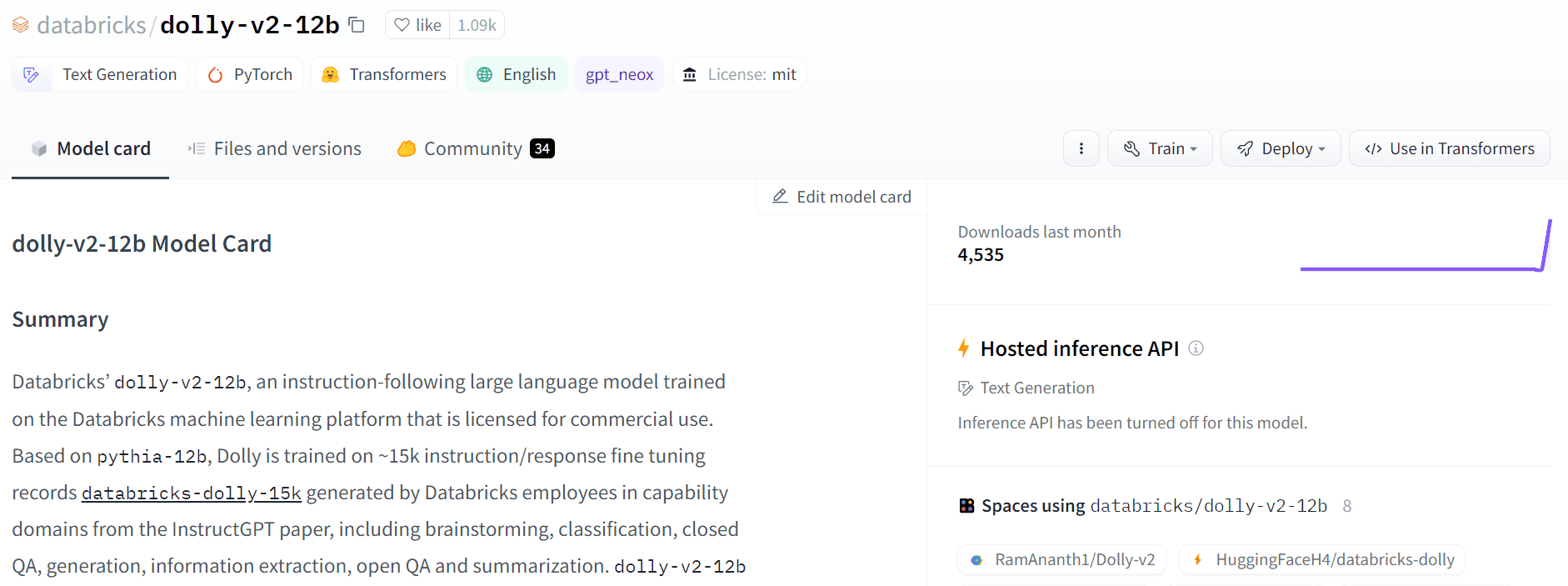
Picture from Hugging Face
Useful resource:
Dolly 2.0 Demo: Dolly V2 by RamAnanth1
Abid Ali Awan (@1abidaliawan) is an authorized knowledge scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in Expertise Administration and a bachelor’s diploma in Telecommunication Engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids scuffling with psychological sickness.




